Jak wdrożyć narzędzia bezpieczeństwa: Ramy 'Pełzanie, Chodzenie, Bieganie'

Podsumowanie: Podejście Fazowe
To krok po kroku podejście pomaga płynnie wdrażać narzędzia bezpieczeństwa i utrzymuje działanie kompilacji. Można je traktować jako serię małych kroków, które chronią proces wysyłki, zapewniając bardziej niezawodny i bezpieczny proces rozwoju.
| Tryb skanowania | Wpływ na dewelopera | Konfiguracja / Ustawienia | Cel i wynik |
|---|---|---|---|
| Crawl Fail Open (Tryb audytu, brak alertów) | Brak zakłóceń; niewidoczne dla deweloperów | Skanowanie przy każdym pushu/commicie, logowanie wyników | Zbieranie danych, dostrajanie reguł, tłumienie fałszywych alarmów; kompilacje zawsze przechodzą |
| Walk Fail Open (Tryb powiadomień, alerty) | Deweloperzy widzą ostrzeżenia w PR/IDE | Włącz dekorację PR/pluginy IDE | Deweloperzy otrzymują konkretne informacje zwrotne, budują zaufanie, dobrowolnie naprawiają problemy |
| Run Fail Closed (Tryb blokowania) | Kompilacje blokowane przy wysokich/krytycznych problemach | Aktywacja bram jakości, blokowanie kompilacji przy nowych krytycznych odkryciach | Zapobiega dotarciu nowych luk do produkcji; deweloperzy szanują niepowodzenia |
Wprowadzenie: Dlaczego „Big Bang” wdrożenia zawodzą
Projekt DevSecOps może szybko zejść na złą drogę przy wdrożeniu „Big Bang”. Często dzieje się tak, gdy zespół otrzymuje nowe narzędzie SAST lub narzędzie do skanowania kontenerów i od razu włącza „Tryb blokowania”. Na przykład, zespół ds. rozwoju oprogramowania w XYZ Corp raz włączył „Tryb blokowania” pierwszego dnia z ich nowym narzędziem skanowania.

Z dnia na dzień narzędzie oznaczyło setki drobnych problemów związanych z bezpieczeństwem, które wymagały pilnej uwagi, skutecznie zatrzymując cały proces rozwoju.
Gdy deweloperzy gorączkowo próbowali rozwiązać te problemy, krytyczne terminy projektowe zostały przekroczone, co prowadziło do frustracji i utraty zaufania do narzędzia. Ten scenariusz podkreśla ryzyko i ilustruje, dlaczego bardziej stopniowe podejście jest konieczne.
Rezultat zazwyczaj prowadzi do problemów:
- Zepsute kompilacje: Deweloperzy nie są w stanie wdrożyć krytycznych poprawek.
- Zmęczenie alertami: Lawina fałszywych alarmów przytłacza zespół.
- Cień IT: Zespoły sfrustrowane omijają kontrole bezpieczeństwa, aby kontynuować pracę.
Aby uniknąć tych problemów, należy przyjąć podejście ewolucyjne zamiast próbować zmieniać wszystko naraz. Na tym polega ramy Crawl, Walk, Run.
Najnowsze badania wykazały, że organizacje wdrażające fazowe wdrożenia doświadczają mierzalnej poprawy częstotliwości wdrożeń i szybszego odzyskiwania po awarii, co zwiększa niezawodność ich praktyk DevSecOps.
Łącząc te ramy z udowodnionymi wynikami wydajności, takimi jak zmniejszony czas przestoju i zwiększone wskaźniki sukcesu kompilacji, możemy zapewnić, że liderzy inżynierii rozpoznają ich wartość.
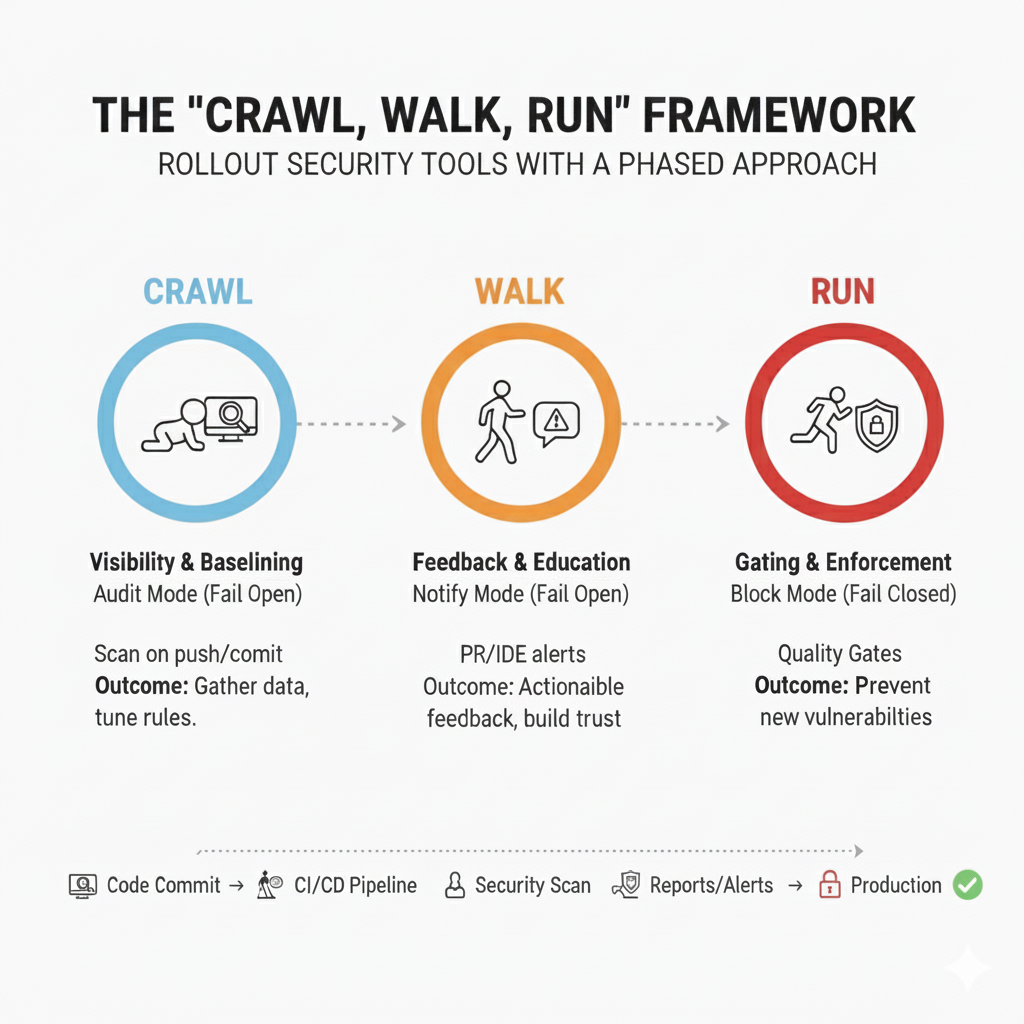
Faza 1: Crawl (Widoczność i ustalanie podstaw)
Cel: Uzyskaj pełną widoczność istniejącego długu technicznego, unikając zakłóceń w przepływie pracy programistów. Dąż do osiągnięcia 90% pokrycia repozytoriów w ciągu pierwszych dwóch tygodni, aby zapewnić mierzalny sukces i jasne punkty odniesienia.
- W tej początkowej fazie skoncentruj się na zbieraniu danych poprzez integrację narzędzia bezpieczeństwa z Twoim potokiem CI/CD w sposób nieinwazyjny.
- Konfiguracja: Ustaw narzędzie na Fail Open, używając trybu audytu — logując wszystkie znaleziska bez powiadamiania programistów lub blokowania kompilacji.
- Działanie: Wyzwalaj skanowania przy każdym przesunięciu kodu lub zatwierdzeniu.
- Wynik: Skaner loguje wszystkie znaleziska na pulpicie nawigacyjnym, jednocześnie pozwalając na pomyślne przejście wszystkich kompilacji, nawet jeśli wykryto krytyczne podatności.
💡 Pro Tip: Wykorzystaj tę fazę do starannego dostrojenia skanera. Jeśli konkretna reguła (np. „Magic Numbers in Code”) generuje nadmierny hałas (np. 500 razy w repozytoriach), rozważ dostrojenie lub tymczasowe wyłączenie jej, aby skupić się na możliwych do podjęcia działaniach przed przejściem dalej.
Dlaczego to jest ważne: Ustanowienie tej „Bezpiecznej Podstawy” pozwala zespołowi bezpieczeństwa zrozumieć wolumen i charakter istniejącego długu technicznego oraz dostosować konfiguracje reguł bez wpływu na wdrożenia.
Faza 2: Chodzenie (Informacja zwrotna i edukacja)
Cel: Zapewnij programistom możliwe do podjęcia, terminowe informacje zwrotne dotyczące bezpieczeństwa, zintegrowane z ich codziennymi przepływami pracy, bez blokowania postępu w rozwoju.
- Po zredukowaniu hałasu, udostępnij wyniki programistom. Utrzymuj narzędzie w trybie Fail Open, ale przełącz na tryb Powiadamiania, włączając alerty.
- Konfiguracja: Zintegruj informacje zwrotne z narzędziami deweloperskimi, takimi jak dekoracja Pull Request (komentarze) lub wtyczki IDE.
- Wynik: Programiści otrzymują informacje zwrotne dotyczące bezpieczeństwa w czasie rzeczywistym w procesie przeglądu kodu, np. “⚠️ Wysoka powaga: Wprowadzono zakodowany sekret w linii 42.”
Programiści mogą zdecydować się na natychmiastowe rozwiązanie problemu lub udokumentowanie fałszywych alarmów do późniejszego rozwiązania.
Dlaczego to jest ważne: Ta faza buduje zaufanie między zespołem bezpieczeństwa a programistami. Bezpieczeństwo jest postrzegane jako współpracujący przewodnik, a nie strażnik. Programiści przyzwyczajają się do obecności narzędzia i zaczynają dobrowolnie naprawiać problemy, ponieważ pętla informacji zwrotnej jest bezpośrednia i możliwa do działania.
Aby wzmocnić te pozytywne zachowania, zachęcaj zespoły do świętowania wczesnych sukcesów. Dzielenie się szybkimi historiami sukcesu, takimi jak ‘pierwszy PR zmergowany bez żadnych wysokich wyników’, buduje momentum i zachęca więcej programistów do dobrowolnych poprawek.
Faza 3: Uruchom (Bramkowanie i Egzekwowanie)
Cel: Zapobieganie przedostawaniu się nowych wysokiego ryzyka podatności do produkcji poprzez egzekwowanie bramek bezpieczeństwa.
- Po dostrojeniu i edukacji deweloperów, aktywuj Build Breakers lub Quality Gates, które egzekwują polityki poprzez blokowanie buildów z krytycznymi problemami.
- Konfiguracja: Ustaw narzędzie w trybie Fail Closed, aby zatrzymać buildy z lukami o wysokiej i krytycznej wadze. Problemy o średniej i niskiej wadze pozostają jako ostrzeżenia, aby uniknąć nadmiernych zakłóceń.
- Ważna subtelność: Rozważ blokowanie tylko nowych luk wprowadzonych przez bieżące zmiany (np. w bieżącym PR), podczas gdy istniejące problemy są śledzone jako elementy backlogu do naprawy w czasie.
- Wynik: Jeśli deweloper wprowadzi, na przykład, krytyczną lukę SQL Injection, build się nie powiedzie i nie może być scalony, dopóki nie zostanie naprawiony lub zatwierdzona dokumentowana zgoda.
Dlaczego to ma znaczenie: Ponieważ narzędzie i zespół są dobrze dostrojeni i wyedukowani, wskaźnik fałszywych alarmów jest niski. Deweloperzy szanują niepowodzenia buildów jako prawdziwe sygnały bezpieczeństwa, zamiast z nimi walczyć.
Co dalej
Teraz, gdy masz fazową strategię, kiedy blokować buildy, następnym krokiem jest decyzja, gdzie zintegrować te narzędzia, aby zmaksymalizować produktywność deweloperów.
W następnym artykule zbadamy Frictionless Security, sposób na bezproblemowe osadzenie narzędzi bezpieczeństwa w IDE deweloperów i przepływach pracy PR, redukując przełączanie kontekstu i zwiększając adopcję.
Najczęściej zadawane pytania (FAQ)
Co to jest framework “Crawl, Walk, Run”?
To prosty, krok po kroku sposób na rozpoczęcie korzystania z nowych narzędzi bezpieczeństwa bez powodowania problemów. Najpierw zbierasz informacje po cichu (Crawl). Następnie pokazujesz programistom problemy, aby mogli się nauczyć i je naprawić (Walk). Na koniec blokujesz zły kod, aby chronić swoje oprogramowanie (Run). To pomaga zespołom płynnie wdrażać narzędzia bezpieczeństwa i zdobywać zaufanie po drodze.
Dlaczego nie powinniśmy od razu blokować budowy?
Jeśli zablokujesz budowy od pierwszego dnia, narzędzie może oznaczyć zbyt wiele problemów naraz, uniemożliwiając programistom wykonywanie ich pracy. Może to powodować frustrację i spowalniać projekty. Rozpoczęcie powoli oznacza, że najpierw znajdujesz i naprawiasz hałaśliwe alerty, więc blokowanie następuje tylko wtedy, gdy narzędzie jest dokładne i zaufane.
Jak długo powinien trwać każdy krok?
Zazwyczaj faza Crawl trwa kilka tygodni, podczas gdy zbierasz wystarczającą ilość danych. Faza Walk zajmuje więcej czasu, ponieważ programiści przyzwyczajają się do widzenia alertów i naprawiania problemów. Przejdź do Run tylko wtedy, gdy narzędzie jest dobrze dostrojone, a zespół czuje się komfortowo z naprawianiem problemów przed scaleniem kodu.
Co to jest „Fail Open” i kiedy go używamy?
„Fail Open” oznacza, że narzędzie znajduje problemy, ale nie zatrzymuje scalania kodu. Używaj tego w fazach Crawl i Walk, aby nie przeszkadzać programistom podczas zbierania danych i uczenia ich o problemach.



