Comment Déployer des Outils de Sécurité : Le Cadre 'Ramper, Marcher, Courir'

Résumé : L’approche par étapes
Cette approche étape par étape vous aide à déployer des outils de sécurité en douceur et à maintenir vos builds en cours d’exécution. Pensez-y comme une série de petites étapes qui protègent votre livraison, assurant un processus de développement plus fiable et sécurisé.
| Mode de Scan | Impact sur les développeurs | Configuration / Installation | Objectif & Résultat |
|---|---|---|---|
| Crawl Fail Open (Mode Audit, Pas d’alertes) | Pas de perturbation ; invisible pour les développeurs | Scan à chaque push/commit, journaliser les résultats | Collecter des données, ajuster les règles, supprimer les faux positifs ; les builds passent toujours |
| Walk Fail Open (Mode Notification, alertes) | Les développeurs voient des avertissements dans les PRs/IDEs | Activer la décoration PR/plugins IDE | Les développeurs reçoivent des retours exploitables, construisent la confiance, corrigent les problèmes volontairement |
| Run Fail Closed (Mode Blocage) | Builds bloqués sur des problèmes élevés/critiques | Activer les portes de qualité, bloquer le build sur de nouvelles découvertes critiques | Empêche les nouvelles vulnérabilités d’atteindre la production ; les développeurs respectent les échecs |
Introduction : Pourquoi les déploiements “Big Bang” échouent
Un projet DevSecOps peut rapidement dérailler avec un déploiement “Big Bang”. Cela se produit souvent lorsqu’une équipe obtient un nouvel outil SAST ou Container Scanner et active immédiatement le “Mode Blocage”. Par exemple, une équipe de développement logiciel chez XYZ Corp a une fois activé le “Mode Blocage” dès le premier jour avec leur nouvel outil de scanner.

Du jour au lendemain, l’outil a signalé des centaines de problèmes de sécurité mineurs nécessitant une attention urgente, interrompant efficacement l’ensemble de leur processus de développement.
Alors que les développeurs s’efforçaient de résoudre ces problèmes, des délais critiques du projet ont été manqués, entraînant frustration et perte de confiance dans l’outil. Ce scénario met en évidence les risques et illustre pourquoi une approche plus progressive est nécessaire.
Le résultat conduit généralement à des problèmes :
- Builds cassés : Les développeurs sont incapables de déployer des correctifs critiques.
- Fatigue des alertes : Un flot de faux positifs submerge l’équipe.
- IT fantôme : Des équipes frustrées contournent les contrôles de sécurité pour faire avancer leur travail.
Pour éviter ces problèmes, adoptez une approche évolutive au lieu de tenter de tout changer d’un coup. C’est ce que le cadre Crawl, Walk, Run propose.
Des études récentes ont montré que les organisations mettant en œuvre des déploiements par étapes constatent une amélioration mesurable de la fréquence de déploiement et une récupération plus rapide des échecs, améliorant ainsi la fiabilité de leurs pratiques DevSecOps.
En liant ce cadre à des résultats de performance éprouvés, comme la réduction des temps d’arrêt et l’augmentation des taux de réussite des builds, nous pouvons garantir que les responsables techniques reconnaissent sa valeur.
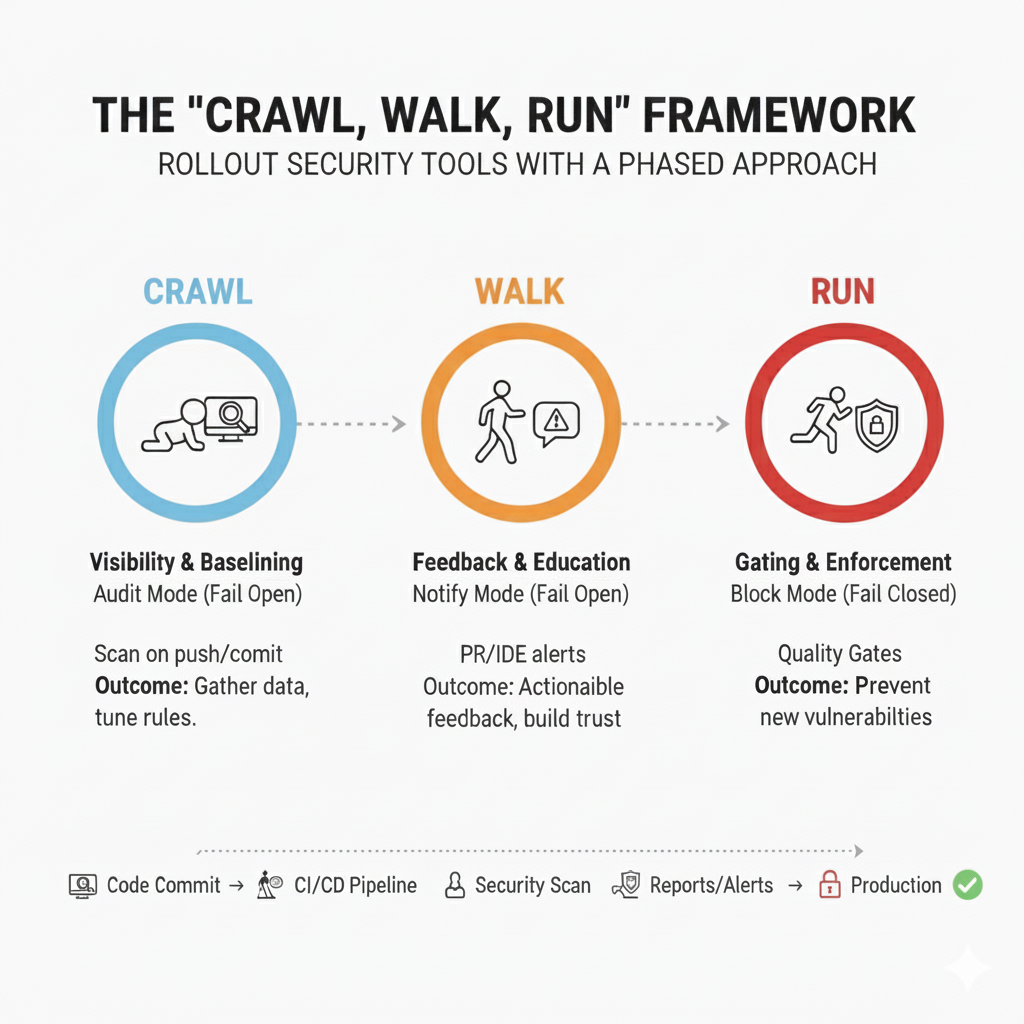
Phase 1 : Ramper (Visibilité & Établissement de base)
Objectif : Obtenir une visibilité complète sur votre dette technique existante tout en évitant de perturber les flux de travail des développeurs. Visez à atteindre une couverture de 90 % des dépôts au cours des deux premières semaines pour garantir un succès mesurable et des points de référence clairs.
- Dans cette phase initiale, concentrez-vous sur la collecte de données en intégrant l’outil de sécurité dans votre pipeline CI/CD de manière non intrusive.
- Configuration : Réglez l’outil sur Fail Open en utilisant le mode Audit—enregistrant toutes les découvertes sans notifier les développeurs ou bloquer les builds.
- Action : Déclenchez des analyses à chaque push ou commit de code.
- Résultat : Le scanner enregistre toutes les découvertes sur un tableau de bord tout en permettant à tous les builds de passer avec succès, même si des vulnérabilités critiques sont détectées.
💡 Conseil Pro : Utilisez cette phase pour ajuster soigneusement votre scanner. Si une règle spécifique (par exemple, “Nombres magiques dans le code”) génère un bruit excessif (par exemple, 500 fois à travers les dépôts), envisagez de l’ajuster ou de la désactiver temporairement pour vous concentrer sur les problèmes exploitables avant de progresser.
Pourquoi cela est important : Établir cette “Ligne de base de sécurité” permet à votre équipe de sécurité de comprendre le volume et la nature de la dette technique existante et de peaufiner les configurations de règles sans impacter les déploiements.
Phase 2 : Marcher (Retour d’information & Éducation)
Objectif : Fournir aux développeurs des retours de sécurité exploitables et opportuns intégrés dans leurs flux de travail quotidiens, sans bloquer le progrès du développement.
- Une fois le bruit réduit, rendre les résultats visibles aux développeurs. Garder l’outil en mode Fail Open, mais passer en mode Notification en activant les alertes.
- Configuration : Intégrer les retours dans les outils de développement tels que la décoration des Pull Requests (commentaires) ou les plugins IDE.
- Résultat : Les développeurs reçoivent des retours de sécurité en temps réel dans leur processus de révision de code, par exemple, “⚠️ Gravité élevée : Secret codé en dur introduit à la ligne 42.”
Les développeurs peuvent choisir de corriger le problème immédiatement ou de documenter les faux positifs pour une résolution ultérieure.
Pourquoi cela est important : Cette phase construit la confiance entre la sécurité et les développeurs. La sécurité est vue comme un guide collaboratif, non comme un gardien. Les développeurs s’habituent à la présence de l’outil et commencent à corriger volontairement les problèmes car le retour d’information est direct et exploitable.
Pour renforcer ces comportements positifs, encouragez les équipes à célébrer les premières victoires. Partager des histoires de succès rapides, comme la ‘première PR fusionnée avec zéro résultat élevé’, crée de l’élan et incite davantage de développeurs à effectuer des corrections volontaires.
Phase 3 : Exécution (Blocage et Application)
Objectif : Empêcher les nouvelles vulnérabilités à haut risque d’atteindre la production en appliquant des barrières de sécurité.
- Après avoir formé et éduqué les développeurs, activez les Briseurs de Build ou les Portes de Qualité qui appliquent des politiques en bloquant les builds avec des problèmes critiques.
- Configuration : Réglez l’outil en mode Échec Fermé pour arrêter les builds avec des vulnérabilités de gravité Élevée et Critique. Les problèmes de gravité moyenne et faible restent des avertissements pour éviter des perturbations excessives.
- Nuance importante : Envisagez de bloquer uniquement les nouvelles vulnérabilités introduites par les changements actuels (par exemple, dans la PR actuelle), tout en suivant les problèmes existants comme des éléments de backlog à remédier au fil du temps.
- Résultat : Si un développeur introduit, par exemple, une vulnérabilité critique Injection SQL, le build échoue et ne peut pas être fusionné tant qu’il n’est pas corrigé ou qu’une dérogation documentée n’est approuvée.
Pourquoi cela importe : Parce que l’outil et l’équipe sont bien réglés et éduqués, le taux de faux positifs est faible. Les développeurs respectent les échecs de build comme de véritables signaux de sécurité plutôt que de les combattre.
À suivre
Maintenant que vous avez une stratégie par étapes pour savoir quand bloquer les builds, la prochaine étape consiste à décider où intégrer ces outils pour maximiser la productivité des développeurs.
Dans le prochain article, nous explorerons Sécurité sans friction, une manière d’intégrer les outils de sécurité de manière transparente dans les IDE des développeurs et les workflows de PR, réduisant les changements de contexte et augmentant l’adoption.
Questions Fréquemment Posées (FAQ)
Qu’est-ce que le cadre “Ramper, Marcher, Courir” ?
C’est une méthode simple et étape par étape pour commencer à utiliser de nouveaux outils de sécurité sans causer de problèmes. Tout d’abord, vous collectez des informations discrètement (Crawl). Ensuite, vous montrez aux développeurs les problèmes afin qu’ils puissent apprendre et les corriger (Walk). Enfin, vous bloquez le mauvais code pour garder votre logiciel sécurisé (Run). Cela aide les équipes à adopter les outils de sécurité en douceur et à gagner en confiance au fil du temps.
Pourquoi ne devrions-nous pas bloquer les builds immédiatement ?
Si vous bloquez les builds dès le premier jour, l’outil pourrait signaler trop de problèmes à la fois, empêchant les développeurs de faire leur travail. Cela peut causer de la frustration et ralentir les projets. Commencer lentement signifie que vous trouvez et corrigez d’abord les alertes bruyantes, de sorte que le blocage ne se produise que lorsque l’outil est précis et fiable.
Combien de temps chaque étape devrait-elle durer ?
Habituellement, la phase Crawl dure quelques semaines pendant que vous rassemblez suffisamment de données. La phase Walk prend plus de temps car les développeurs s’habituent à voir les alertes et à corriger les problèmes. Ne passez à Run que lorsque l’outil est bien réglé et que l’équipe est à l’aise pour corriger les problèmes avant que le code ne soit fusionné.
Qu’est-ce que “Fail Open” et quand l’utilisons-nous ?
“Fail Open” signifie que l’outil trouve des problèmes mais ne bloque pas la fusion du code. Utilisez cela dans les phases Crawl et Walk pour éviter de perturber les développeurs pendant que vous collectez des données et leur enseignez les problèmes.



